
Activation Functions 激勵函數
見的激勵函數選擇有 sigmoid, tanh, Relu,實用上最常使用 ReLU ,一些變形如 Leaky ReLU, Maxout 也可以試試,tanh 和 sigmoid 盡量別用。
在深度學習領域 Relu 激勵函數蔚為主流,主要考量的因素有以下幾點:
1. 梯度消失問題 (vanishing gradient problem)
2. 類神經網路的稀疏性
3. 生物事實:全有全無律
4. 計算量節省
softmax這個常用於最後一個激勵函數
softmax:值介於 [0,1] 之間,且機率總和等於 1,適合多分類使用。
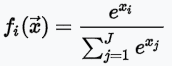
輸入向量對應的Softmax函數的值為[0.024,0.064,0.175,0.475,0.024,0.064,0.175]。輸出向量中擁有最大權重的項對應著輸入向量中的最大值「4」。這也顯示了這個函數通常的意義:對向量進行歸一化,凸顯其中最大的值並抑制遠低於最大值的其他分量。
![{\displaystyle [1,2,3,4,1,2,3]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d068344b5d5265343f7fdf213e30f73afe408278)
下面是使用Python進行函數計算的示例代碼:
import math z = [1.0, 2.0, 3.0, 4.0, 1.0, 2.0, 3.0] z_exp = [math.exp(i) for i in z] print(z_exp) # Result: [2.72, 7.39, 20.09, 54.6, 2.72, 7.39, 20.09] sum_z_exp = sum(z_exp) print(sum_z_exp) # Result: 114.98 softmax = [round(i / sum_z_exp, 3) for i in z_exp] print(softmax) # Result: [0.024, 0.064, 0.175, 0.475, 0.024, 0.064, 0.175]
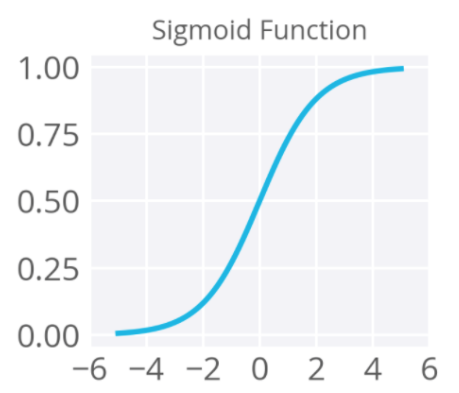
- sigmoid:值介於 [0,1] 之間,且分布兩極化,大部分不是 0,就是 1,適合二分法。
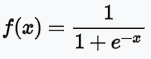
- Relu (Rectified Linear Units):忽略負值,介於 [0,∞] 之間。
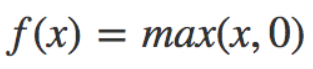
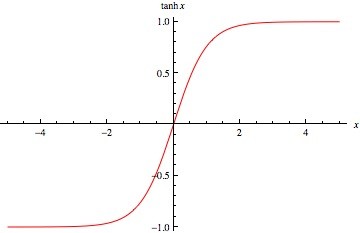
- tanh:與sigmoid類似,但值介於[-1,1]之間,即傳導有負值。
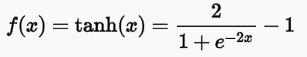
什麼是 One-hot encoding?
One-hot encoding 是將類別以 (0, 1) 的方式表示,舉例來說,假設有 cat、dog、bird 三個類別,而三個類別可以用 (1, 0, 0)、(0, 1, 0)、(0, 0, 1) 來表示。

之所以用 One-hot encoding 的原因是,一般來說,我們在做 Classification 時,其資料的 label 是用文字代表一個類別,例如做動物的影像辨識,label 可能會是 cat、dog、bird 等,但是類神經網路皆是輸出數值,所以我們無法判斷 34 與 cat 的差別。因此,One-hot encoding 便是在做 Classification 經常使用的一個技巧。
雖然 One-hot encoding 經常在 Classification 中被使用,但是它不是沒有缺點,假設欲分類的類別過多,可能會造成「維數災難」的問題。
About Author
DAVIDOU
一個不務正業,甚麼科技產品都玩的網路宅宅。 If you want to find me,that's easy! I will always on the Internet. so just find me, follow me. I will show you everything fun.
我的社群網路


